% Pipedream - Generalized Pipeline Parallelism for DNN Training % Authors from MSR + CMU + Stanford; Presentation & Interpretation by laekov % July 14
DNN Training 的三种并行模式
Data Parallel (DP)
- 沿 batch 维度进行切分
- 通信: 同步 weight
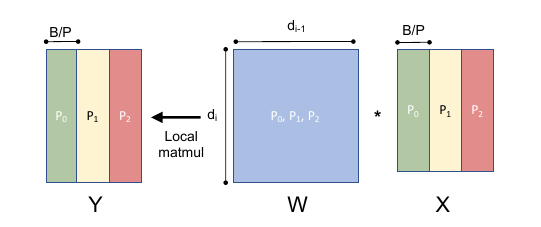
Model Parallel (MP)
- 沿 weight 维度进行切分
- 通信: feature tensor 的求和或者拼装

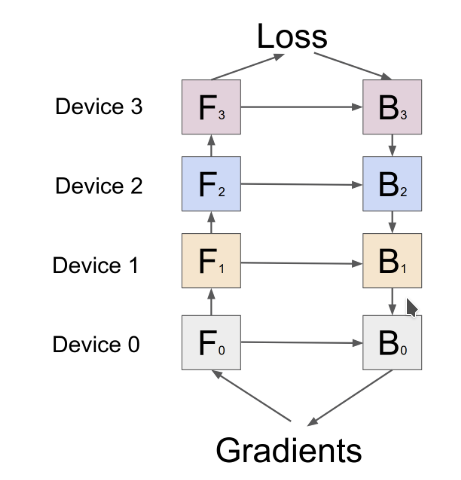
Pipeline Parallel (PP)
- Inter-layer partition
- 通信: 切口处的 feature tensor 及它们的梯度 (在部分模型中通信更少)
- Overlap 通信和计算 (DP 的 lazy update 也算 pipeline 的一种)
Inter-batch Parallelism
无并行的 pipeline
- 分摊 weight 所需显存
- 支持不同规格加速器混用
- 在 homogeneous 环境下毫无加速
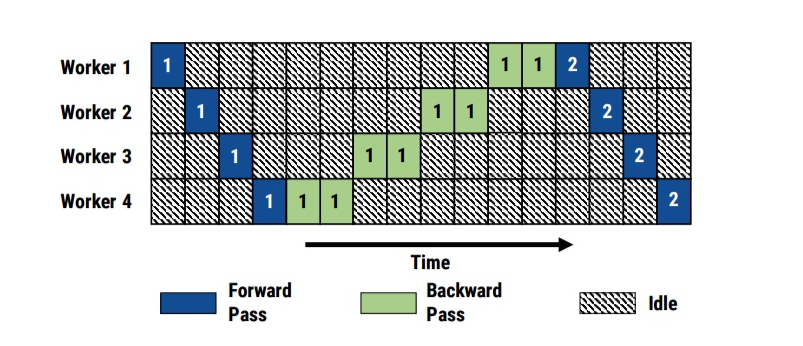
GPipe 并行: 批处理模式
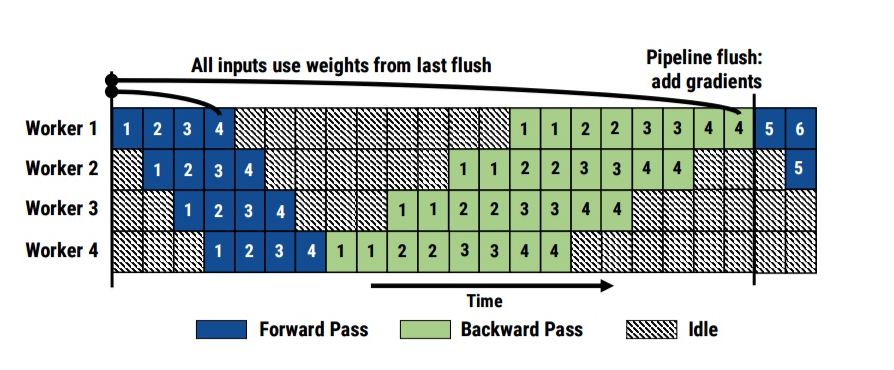
Pipedream 并行
- 多发射
- forward 和 backwoard 交错进行
- 可填满流水线
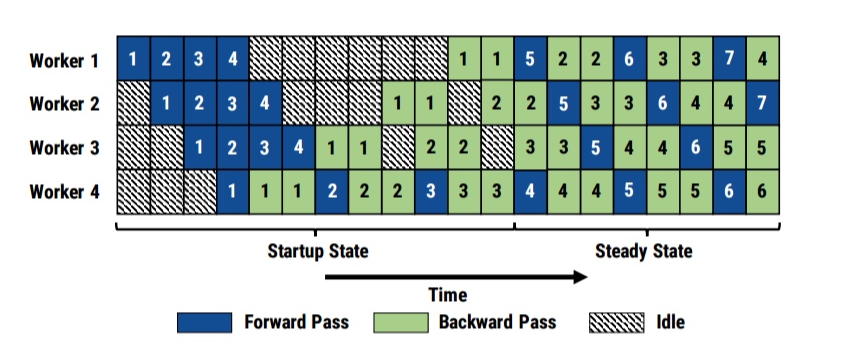
计算通信 overlap
- 由 pytorch 框架实现.

自动 pipeline 划分
Workflow
- Profile: 对于一个模型, 单独跑每个 layer, 记录 latency.
- Optimize: 根据 profile 结果和网络带宽 (用户输入) 进行 partition.
- Runtime: 作为 pytorch / caffee 的插件, 使用 optimizer 的输出作为模型. (通信使用 gloo)
Optimizer 的动态规划算法
- 假设 layers 是 sequential 的.
- 设 $A^k(i\to j, m)$ 表示从 $i$ 到 $j$ 使用最高 $k$ 层的 $m$ 个 worker 的 pipeline 最小代价.
- 设 $T^k(i\to j, m)$ 表示 (同上条件下) 使用 dp 的最小代价.
- $A$ 和 $T$ 使用区间动态规划互相转移. (具体式子见原文)
- 结果是 DP 和 PP 混合进行.
Active batches
- 需要精确计算 active batches 的数量 $NOAM$
- 需要保留 $NOAM$ 份 weight 来做 BP, 引入额外 memory overhead.
- 引入了 update staleness, 但在可以接受的范围内.
实现和实验
- 3000 行 python 代码, 作为 pytorch 上面的一层 (也可以使用 caffe 或者移植到别的框架上)
- 在 4x V100 PCIe / 8x V100 SMX 两种节点的集群上实验
- 在 CV 和 NLP 的不同模型上实验
- 和 LARS (允许更大 batch size), Asynchronized training 对比, 数值上更有效
- 和 Gpipe 和其它 MP 对比跑得更快.
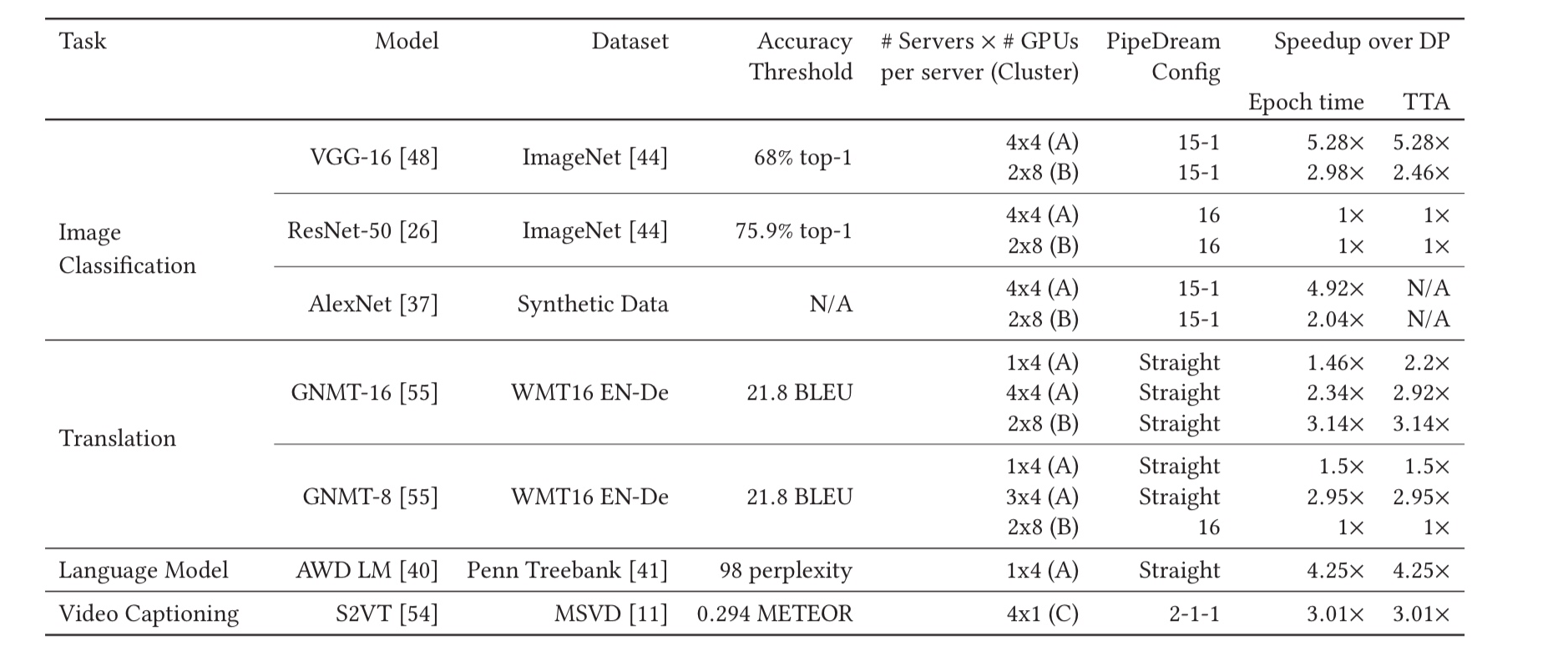
分析
优势
- 可以减小 batch size
- 在部分模型上减少 communication
问题
- staleness 及 memory overhead
- 使用起来有复杂性
- 切分方式局限, 只能切分近似 sequential 的模型
- 对 network bandwidth 的考虑较为简单