这是一篇 arxiv 文章 的中文简要版本.
摘要
这篇文章主要介绍了一种大语言模型的推理系统. 在自回归生成过程中, 序列中的元素 (token) 被挨个生成, 因此模型推理的序列长度 (sequence length) 为 1.
因此, 增大 batch size 对于 GPU 利用率的提升十分重要. 然而 KV-Cache 体积很大, 且与 batch size 成正比.
其大小阻止了 batch size 和 GPU 利用率的提升.
相比 vLLM 提出的 page attention 技术, FastDecode 对于 CPU 的利用进行了更加大胆的尝试. 其不仅利用了 CPU 的内存容量, 还利用了其计算能力和多机扩展能力, 从而达到了提升 batch size, 提升 GPU 利用率的目的, 并实现了端到端的推理吞吐量提升.
背景
在自回归生成过程中做 attention 时, 一个 token i 的特征向量 (feature vector) 会线性映射拆成 Qi, Ki, Vi 三个特征向量.
其中, Qi 用于与序列中之前所有的 Kj, Vj 向量做 attention, 从而得出输出特征向量 Oi.
而 Ki, Vi 则会被留存下来, 以便之后的 token 在做 attention 时不再重复计算.
用于留存序列中 Ki, Vi 的存储空间 (或者是这个张量) 被称为 KV-Cache.
众所周知, GPU 的利用率取决于 batch size 的大小. 因此, 在自回归生成时, 如果能有成百上千的序列一起生成, 那么 GPU 才能被利用得比较好.
然而对于一个 7b 的模型来说, 一个长度为 1024 的序列的 KV-Cache 就有 0.4GB. 200 个序列就是 80GB. 这对于 GPU 显存来说是不友好的.
如果使用 vLLM 提出的 page attention 技术, 将 KV-Cache 分页卸载 (offload) 到主存, 由于 KV-Cache 需要在生成每个 token 的时候都被使用到, 那么这 80GB 的数据会反复在 CPU 和 GPU 之间腾挪.
这对于并不富余的 PCIe 带宽来说无疑是一个沉重的负担.
译注: PPoPP'24 会上 Nir Shavit 的 keynote 演讲中 background 部分和这里完全一样. 但是他接下来就开始讲如何在 attention 上做稀疏化的算法来解决这一问题. 而这篇文章提出的解决方案更为直接, 在不修改任何模型和算法的前提下优化这件事情.
FastDecode 设计方案
拆分 Attention
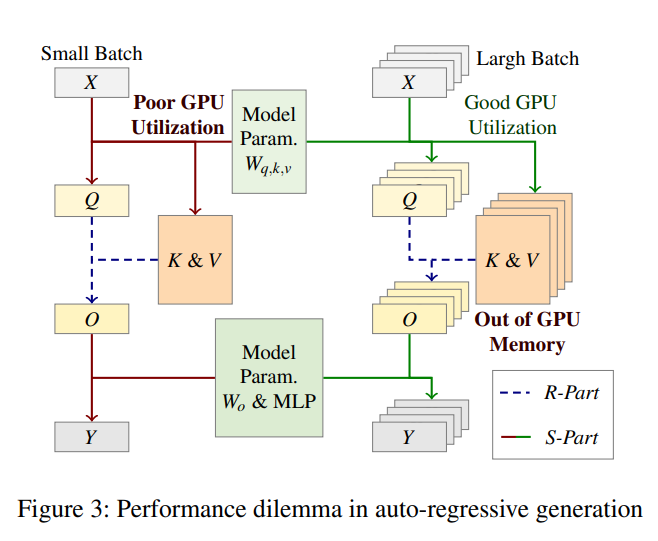
注意到, 生成了 Qi, Ki, Vi 之后到获得 Oi 之前这段计算是不需要任何模型参数参与计算的.
而这里也包含了占用了海量内存的 KV-Cache.
另外值得注意的是, 当 batch size 增大的时候, KV-Cache 的计算效率并不会随之提升, 因为对于每个序列来说, 它们的 KV-Cache 是互相独立的.
因此, 扩大 batch size 对于 KV-Cache 来说只是将原来的一份工作量变成了多份工作量, 而其本质上还是对于 KV-Cache 的一次内存遍历, 是一个内存密集型任务.
我们把这一段计算称作 R-Part.
相对应的, Transformer 模型里的其它部分的计算基本都是参数矩阵和特征向量之间的矩阵-向量乘法. 大扩大 batch size 之后就变成了被大量优化过的矩阵-矩阵乘法 (GeMM). 我们把这部分称作 S-Part.
把 R-Part 的计算和内存一起挪到 CPU
R-Part 的计算吞吐量本质上是和访存吞吐量基本相同的. (注: share KV 会导致这里有一些不同, 但不改变其访存密集的本质) 因此, 把 R-Part 的计算也放到 CPU 上做, 并不会对其效率产生太大影响. 额外地, 把 KV-Cache 从主存倒腾到 GPU 显存的带宽也一定不大于主存的带宽, 所以这种做法是严格比把 KV-Cache 给 offload 更优的.
而传递 Qi, Ki, Vi, Oi 的通信量相比于 KV-Cache 的大小是 2/S (S 表示序列长度).
所以这种做法额外产生的通信开销也是相对较小的.
一个新的问题是主存带宽相比昂贵的 GPU HBM 还是慢的. 这个问题的解决方案是: 主存的带宽和容量是好扩展的! 相比焊死在 GPU 上的 HBM 颗粒, 不论是往机箱里插更多的内存条, 还是直接使用更多的 CPU 节点, 都可以很好的扩充主存的聚合带宽和容量, 从而提升 R-Part 的计算性能.
这样一来, 就得到了如下的 FastDecode 系统.
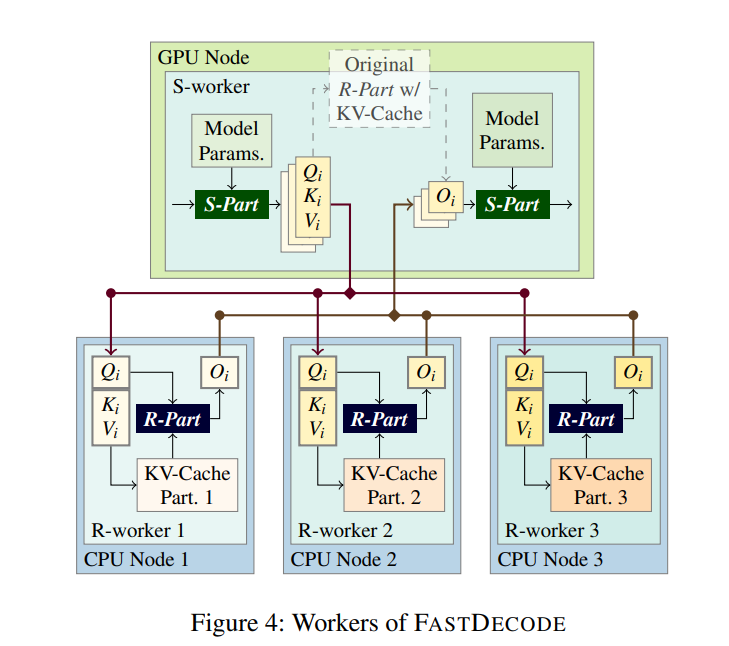
相比于一个纯使用 GPU 推理的系统, FastDecode 劫持了 R-Part 的计算, 使用多个远程的 CPU 节点来存储不同序列所对应的 KV-Cache, 并利用它们来计算相应的 R-Part. 最终返回一个和在 GPU 上计算相同的结果 Oi.
异构流水线及其调度
现在 GPU 和 CPU 轮流工作, 所以必然要用一个二级流水同时处理两个小 batch, 从而使得两个硬件都被充分利用. 如下图所示.

一个新的挑战在于: 这种流水线要求 S-Part 和 R-Part 的工作时间尽量相等, 否则效率会变低. 然而 S-Part 的延迟只和 batch size 相关, R-Part 的延迟却是和所有序列的总长度正相关. 如果处理同一个 batch, 这就会导致 R-Part 的时间从短逐步变长, 从而导致一些时间的浪费.
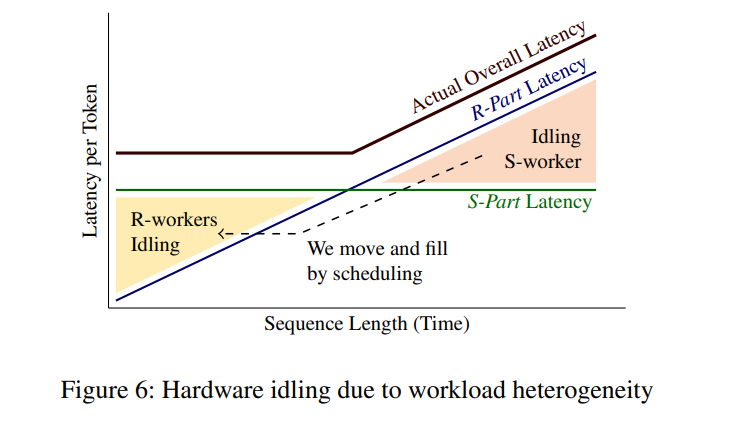
如上图所示, 我们要想办法让 R-Part 延迟超出 S-Part 的部分填到 R-Part 比较快的部分里. 这就引入了一种新的调度方法.
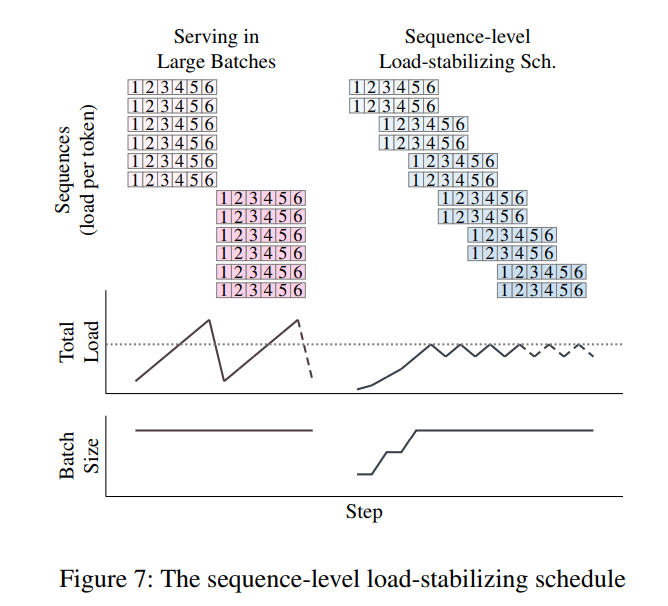
简单来讲, 每隔一段时间向流水线里加入一个小 batch, 这样就可以使得正在处理的序列总是有长有短, 而它们的总长度保持相对稳定.
在匹配 GPU 和 CPU 数量的时候, 使用这个相对稳定的延迟作为参考, 就可以让流水线尽量被填满了.
系统实现及实验结果
FastDecode 基于 PyTorch 实现. 对于模型并行, 量化等都具备天生的兼容性.
文章中使用一到两块 A10 GPU 和 4 台双路 AMD Epyc CPU 服务器进行了实验, 机器之间使用 Infiniband 连接. 在使用相同的 GPU 时, FastDecode 比 TensorRT-LLM, vLLM 等系统获得了 1.88 - 8.7 倍的吞吐量提升.
虽然提升的 batch size 对延迟有一定影响, 但也在可接受范围内. 相比于 vLLM, 其提供的服务延迟更加稳定, 没有 swap 所带来的极高的长尾延迟.
(具体实验数据详见原文)
总结和讨论
笔者愿称此文为一种 “大胆” 的尝试. 在神经网络训练/推理领域, 使用主存来进行 offload 的工作并不少见. 但使用 CPU 的计算能力来替代一部分 GPU 上的运算, 初听起来实属天方夜谭. 而 FastDecode 挖掘并解耦出了 Transformer 模型自回归生成任务中最适合 CPU 的部分, 并利用 CPU 服务器的易得性和可扩展性来实现与 GPU 相当的吞吐量, 从而将 GPU 从繁重的内存密集型任务中解放出来, 使其能更专注且高效地完成它擅长的 GeMM, 最终实现了端到端的推理吞吐量提升.
现实中, 目前 GPU 是十分紧俏的资源, 而 CPU 作为一种传统且大量部署的硬件, 其易得性无疑是更好的. 虽然本文对于成本的计算并不那么精准, 但笔者相信这个系统能在一些场景中找到存在的意义, 并发挥它的价值.
另外, 文章也提到, 其实 CPU 并非计算 R-Part 的终极解决方案. 如能力较弱的 GPU, FPGA, 甚至是专用加速器, 使用 CXL 连接的内存池, 都有用作 R-Worker 的潜力. 而文中提出的分布式设计和在异构硬件上实现流水线的技术在这些场景中是通用的.