版权声明: 如需转载请先与 laekov 联系, 侵权必究.
序
Jiaao He 在 24 岁生日那一天收到邮件, 他在 ppopp 投稿的这篇文章被接收了. 这是他以一作身份投的第一篇 A 类会文章.
laekov 当时脑子一热, 开了一个坑, 决定把这篇文章的主要内容用中文写出来, somehow 地促进中文学术. (虽然多半并没有什么帮助)
在过去的小半年里他又经历了 artifact evaluation, camera ready, 制作 presentation slides 和录制视频 (很遗憾因为疫情没法去韩国开会了) 等等一系列事情, 对这个项目也有了更多的理解. 在 4 月的第一天终于把写文章时候的 prototype 变成了看起来还不错的代码, 并准备合并进 FastMoE. 正好写完这篇文章, 也当作是在 FastMoE 里使用 FasterMoE 的中文版文档了.
这篇文章的 pdf 正文在 ACM DL 上可以找到. (有 open access, 在任何地方都可以下载, 并用于非商业目的) 开会的时候用的 slides 和视频链接 在这里.
背景和简介
我假设看这篇文章的人已经知道什么是 MoE 模型了, 大规模的 MoE 模型现在有多重要 (也可能并不). 专家并行模式 (即 gshard 模式) 是如何把 expert 们分布式地放在所有 worker 上, 并使用 all-to-all 通信方式把输入发送到 expert 上的.
如果你不知道, 一言以蔽之, 负载如下图.
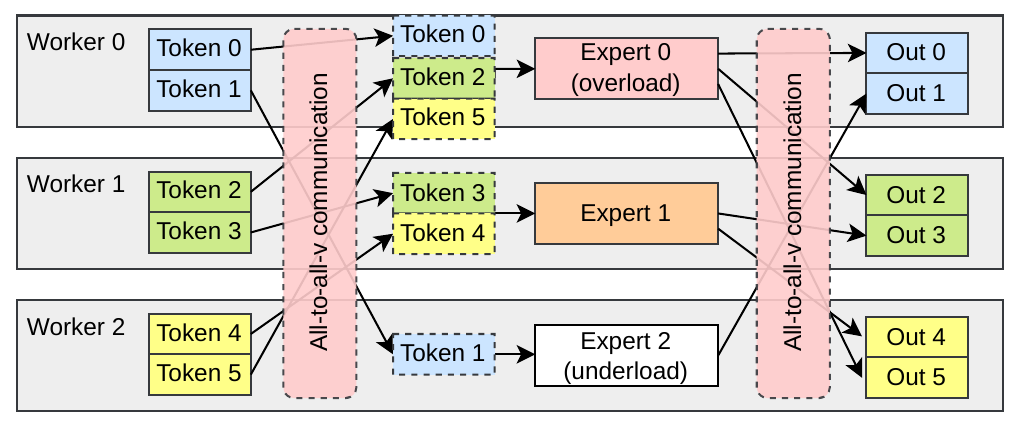
这里面就有三个性能问题:
- 负载不均衡. 不同的 expert 收到的输入数目不同, 因此处理时间不同. 处理得快的要花很长的时间等处理得慢的.
- 集合通信算子效率低: 要等整个 all-to-all 操作发完所有数据之后才能继续进行操作, 对于计算和通信的硬件资源都有比较大的浪费.
- 网络负载比较重:
all-to-all数据量不小.
针对这三个挑战, 我们 (laekov) 发明了三个优化方式, 并引入了一个 DDL-Roofline 模型来从理论上刻画这个负载的特点.
优化点
影子专家 (Expert Shadowing)
针对负载不均衡的问题, 进一步观察真实模型中的专家选择情况, 可以发现一些专家显著地比另一些专家更热门, 但是其趋势也是每轮 / 每层都不一样的.
影子专家技术的核心是将热门专家的参数进行广播. 对于需要该专家处理的输入, 不再发送到对应的 worker 上进行计算, 而是在本地使用广播出来的参数进行计算. 这样, 虽然广播引入了额外的通信开销, 但是可以摊热门专家带来的更严重的负载不均的问题, 从而给性能带来好处.
具体来讲, 我们使用了一个性能预测器来帮助决定每一轮迭代中影子专家的选择. 将所有专家按照热度排序后, 从高到低依次判断将其设为影子专家是否会带来性能收益.
细粒度调度 (Smart Scheduling)
前面提到 all-to-all 集合通信是一个粗粒度的算子, 阻碍了将计算和通信进行重叠. 因此, 需要将其打碎为若干小的操作, 然后再进行细粒度调度. 参考 pair-wise exchange 算法, 我们使用 group-wise exchange 算法来拆分 all-to-all, 然后再重排, 如下图. (其中 S 代表第一次 all-to-all 的一部分, C 代表对于对应的输入进行的计算, R 代表第二次 all-to-all 的一部分)
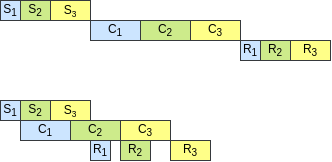
通过这样的重排, 通信时间和计算时间就有效地减少了. 对于影子专家的计算和通信, 也可以很好地整合进这个调度里面.
考虑网络拓扑的门网络 (Topology-aware Gate)
不同于上两个优化点, 这个优化点对算法进行了一些改变. 此外, 我们强调,针对不同的网络拓扑结构, 需要进行专门的设计. 此处我们的设计仅作为一个例子来展示这样的系统-模型联合设计的方法.
考虑多台机器, 每台机器里有多个 GPU 的情况, 一机内的 GPU 之间网络带宽显著地比机器之间快. 但是如果对专家选择不加以限制, 那么显然更多的输入会被发送到不同机器上的 GPU 上, 那么机器之间的网络就拥塞了, 而机器内 GPU 之间的网络比较空闲.
参考 GShard 和 BASE Layers 的做法, 我们也对专家的选择进行人为干预, 但更进一步, 我们考虑硬件连接的拓扑关系. 我们限制跨机器选择专家的输入数量. 不同于 GShard, 我们让多余的输入按照分数重新在本节点内选择一个喜欢的专家来进行处理. 这样, 我们不仅降低了通信开销, 还更充分地利用了训练数据 (GShard 扔掉了它们).
如何在 FastMoE 中使用这些优化
Expert Shaodwing
为了方便 (因为 laekov 懒), 这个特性必需和 Smart Scheduling 一起使用. 每个专家必需结构完全相同.
使用环境变量 FMOE_FASTER_SHADOW_ENABLE=1 或 ON 来使能这个特性.
源代码 fmoe/fastermoe/shadow_policy.py 中定义了默认的影子专家选择算法, 它假设用户的专家是一个两层前馈网络 (MLP). 用户可以自定义这个算法, 记得在修改后需要重新安装一次 FastMoE.
在默认的算法中, 可以使用以下一些环境变量来控制专家选择算法.
FMOE_FASTER_GLBPLC_NETBW是 GPU 之间的连接带宽, 以GBps为单位.FMOE_FASTER_GLBPLC_GPUTP是 GPU 进行矩阵乘的吞吐量, 以FLOPs为单位. 例如 NVIDIA V100 的单精度浮点性能约为13e12.FMOE_FASTER_GLBPLC_ALPHA是每个 MLP 层的中间激活向量长度与输入或输入向量长度的比值. 在 Transformers 模型里通常是2或者4.FMOE_FASTER_GLBPLC_DMODEL是输入或输出特征向量的长度. FastMoE 可以自动从输入中判断这个值, 不必特别设置.
Smart Scheduling
这个特性也有一些限制. num_expert必需设为1. (还是因为 laekov 懒. 期待来自开源社区的贡献能够把其它情况给支持了) 专家的输入和输出的向量长度必需等.
用环境变量 FMOE_FASTER_SCHEDULE_ENABLE=ON 来开启这个特性. 用 FMOE_FASTER_GROUP_SIZE 这个环境变量可以调 Group-wise exchange 的 group 大小, 从而在流水任务太少导致气泡和粒度太细低效之间找一个平衡.
Topology-aware Gate
这个模块在 FastMoE 里面被改名叫了 FasterGate, 和其它 gate 的使用方式一致. FMOE_TOPO_GPUS_PER_NODE 环境变量控制每节点内的 GPU 数. FMOE_TOPO_OUTGOING_FRACTION 表示允许被发到其它节点的输入条目的比例.
DDL-Roofline 模型
DDL 的意思不是 Deadline, 而是 Distributed Deep Learning.
这个 Roofline 和传统的 Roofline 不太一样. 画出来如下.
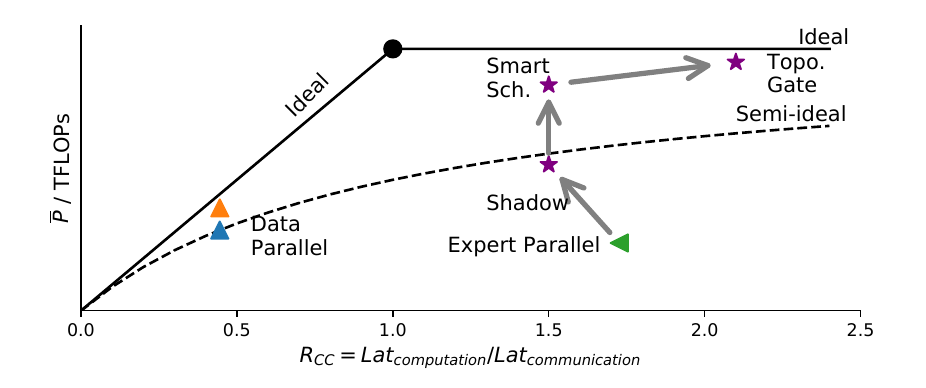
其中横轴是计算时间与通信时间的比值 (传统 Roofline 的是访存量), 纵轴是每加速器的平均计算吞吐量.
实线是理想线, 是真正的屋檐线. 但它的前提条件是通信能够完美地被计算所遮盖. 虚线是一条半理想线, 表示计算和通信完全不做重叠. 事实上, 在很多现在的 DL 框架里面, 这样的重叠都是需要特定条件或者手工进行的. 比如在原来的 FastMoE 里, 因为各种问题, 就没有做这样的重叠. 这种时候, 峰值性能就会被这条半理想线所限制.
一个例子是数据并行的两个点. 蓝点表示的是不重叠的数据并行, 因为没有负载不均衡的问题, 所以它可以达到半理想的线. 而橙点表示数据并行的反向计算可以和梯度同步所重叠, 所以它在虚线上面. 但数据并行的问题是在 MoE 模型中, 参数量相对比较大, 而计算量因为被稀疏化过了, 所以相对比较小. 因此它在横轴上的位置很靠左, 优化再好性能也不会怎么好. 实验中我们的系统也确实暴打了使用 DeepSpeed 的 ZeRO Optimizer 来训 MoE 的 baseline. (而彼时 DeepSpeed 的专家并行模式还远未诞生)
绿色是专家并行. 在 MoE 中, 专家并行的通信量是远小于数据并行的, 但它的问题是负载不均, 所以它虽然在右边, 但比较靠下. 我们的 Expert Shadowing 正好缓解了负载不均的问题, 因此计算延迟变小了, 但性能却变高了. 进一步的, Smart Scheduling 使得计算和通信可以重叠在一起, 于是我们超过了半理想线. 而 Topology-aware Gate 直接通过改变负载来减小了通信量, 从而性能更好.
实验结果
略了. 见原文.
题外话: PPoPP'22 的另一篇文章: 八卦炉 BaGuaLu
ACM DL 链接 (同样有 open access)
这是一篇 Jiaao He 作为二作的文章, 是一个巨大的工作 (其实是试图冲击 GB, 失败). 合作方有之江实验室, 清华的 KEG 实验室, 阿里达摩院, 北京智源研究院. 其主要贡献是在中国国产的神威超级大规模的计算机上训练了一个史无前例的 130 万亿的大模型. 其中 Jiaao 的主要贡献是在分布式方面, 包括开发和移植 FastMoE, 设计并行方案, 准备和跑大规模 (大几万个进程的那种) 实验. 因为和 FastMoE 相关, 故也在这里也将 Jiaao 贡献了的部分顺带一提.
与 FasterMoE 不同, BaGuaLu 解决主要问题是在特定平台训练特定模型, 因此在分布式的设计上也更加特化.
具体来讲, BaGuaLu 使用了数据并行和专家并行混合的方案, 并进行了 topology-aware 的设计.
在数据并行的维度上使用了改进过的 ZeRO Optimizer 的思路, 来存储大模型.
发明了 SWIPE 这样一个又快又能保证 完美负载均衡 的 Gate, 虽然它并不 topology-aware. 这个 Gate 也被用到了后来提出的 AIPerf-MoE 中.
事实上, 这个工作更大的难度是在国产的完全不同的体系结构上构筑出一套完整的深度学习环境, 包括算子库, DL 库等等. 而这里面 Zixuan 和其他同学做出了更加艰巨且重要的贡献. 在文章里这一部分也有详细展开.
Historical Comments
laekov at 2022-03-24T12:04:03
昨天刚录完英文版视频, 感觉自己已经不会说英文了… 以及这个坑大概率要咕了.